Architecture
Overview
Here is a basic overview of the components interacting in a typical PHAIDRA instance. The blue boxes are part of PHAIDRA repository.

Now we'll try to explain the role these components play in the repository:
OCFL
All digital object's data and metadata are stored on a filesystem using the Oxford Common Filesystem Layout standard (with Fedora Repository extensions). Ideally, it contains all information necessary to reconstruct the repository during a disaster recovery. This includes the binaries and all the metadata: metadata describing the digital object provided from the user as well as preservation metadata necessary to understand the structure of the repository and the relationships between the objects, verify the integrity of all files and enable authorization.
Fedora Repository
Fedora Repository is a toolkit implementing many critical repository features using well defined standards and best practices.
Fedora DB
Fedora Repository keeps it's own index of the content to enable efficient management of the filesystem, the linked-data platform features, etc.
Fixity
This component executes periodic check of the integrity of files using Fedora Repository's fixity functionality.
PHAIDRA API
To represent a common, yet flexible platform for many different use cases, Fedora Repository does not define the composition of a digital object, what metadata will be used to describe it, how the repository is structured or what workflows exist. Each repository built on top of Fedora Repository has define and implement these aspects on it's own. In PHAIDRA, most of this logic can be found in phaidra-api. It implements all parts of object's lifecycle, from ingest to re-use and dissemination, as well as authentication and authorization.
Phaidra DBs
A MariaDB and a MongoDB are used. In the SQL database we keep usage statistics, fixity information, terms of use, or the PID counter. The document database on the other hand is used for session data, user groups, metadata templates, OAI records, application settings and as a job queue for backend scripts.
Solr
The search engine is the fastest way to inspect the contents of the repository and it is used in frontend as well as backend. Currently the Lucene based Apache Solr search engine is used.
IIIF Imageserver
The imageserver is used to generate thumbnails (for pictures and PDF documents) as well as pyramid images for imageviewers and bookviewers.
PHAIDRA Vue Components
Right from the early days of PHAIDRA there was a need for more than just one frontend for the repository. This led not only to PHAIDRA API implementing many features which would be typically left for frontend (i.e. providing various data viewers which the frontend merely embeds via iframe) but also to the creation of reusable frontend components. PHAIDRA Vue Components is a library of Vue components and scripts which implement many common use cases: ingest, metadata editing, defining relationships and access rights, search, etc. It enables fast development of tailored frontends (see Docked Applications for examples) while also keeping them thin, hence easier to maintain.
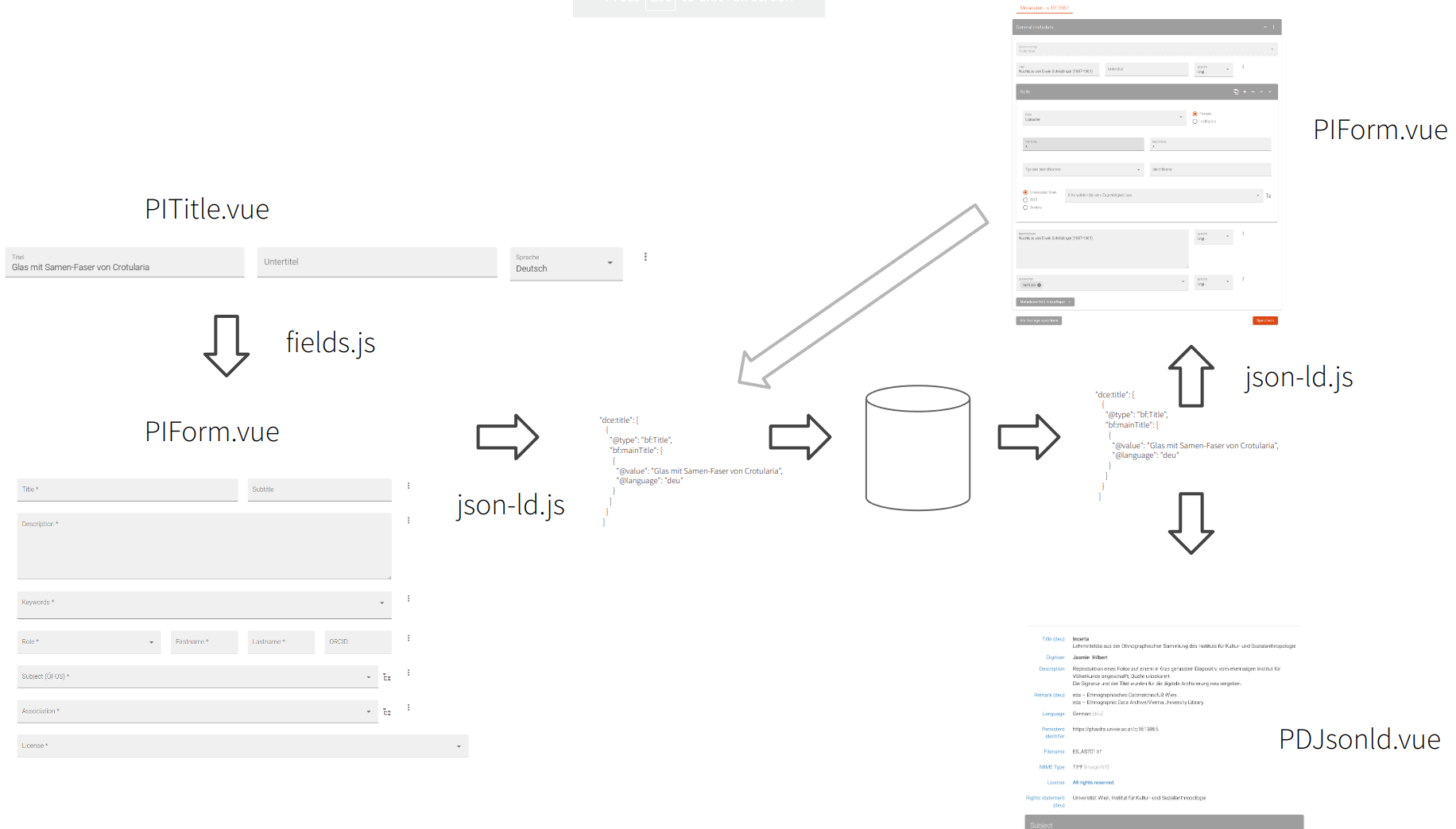
Here is a little schematics which summarizes how the parts of PHAIDRA Vue Components work together:
PHAIDRA UI
This is the general purpose frontend for PHAIDRA. It provides access to almost all features of the repository and mostly builds on PHAIDRA Vue Components. It's aim is to be intuitive, so that it can be used by users without expert knowledge of repositories or bibliographic or other metadata, and also agnostic to where the digital object is coming from, since objects can be ingested via many different frontends and systems.
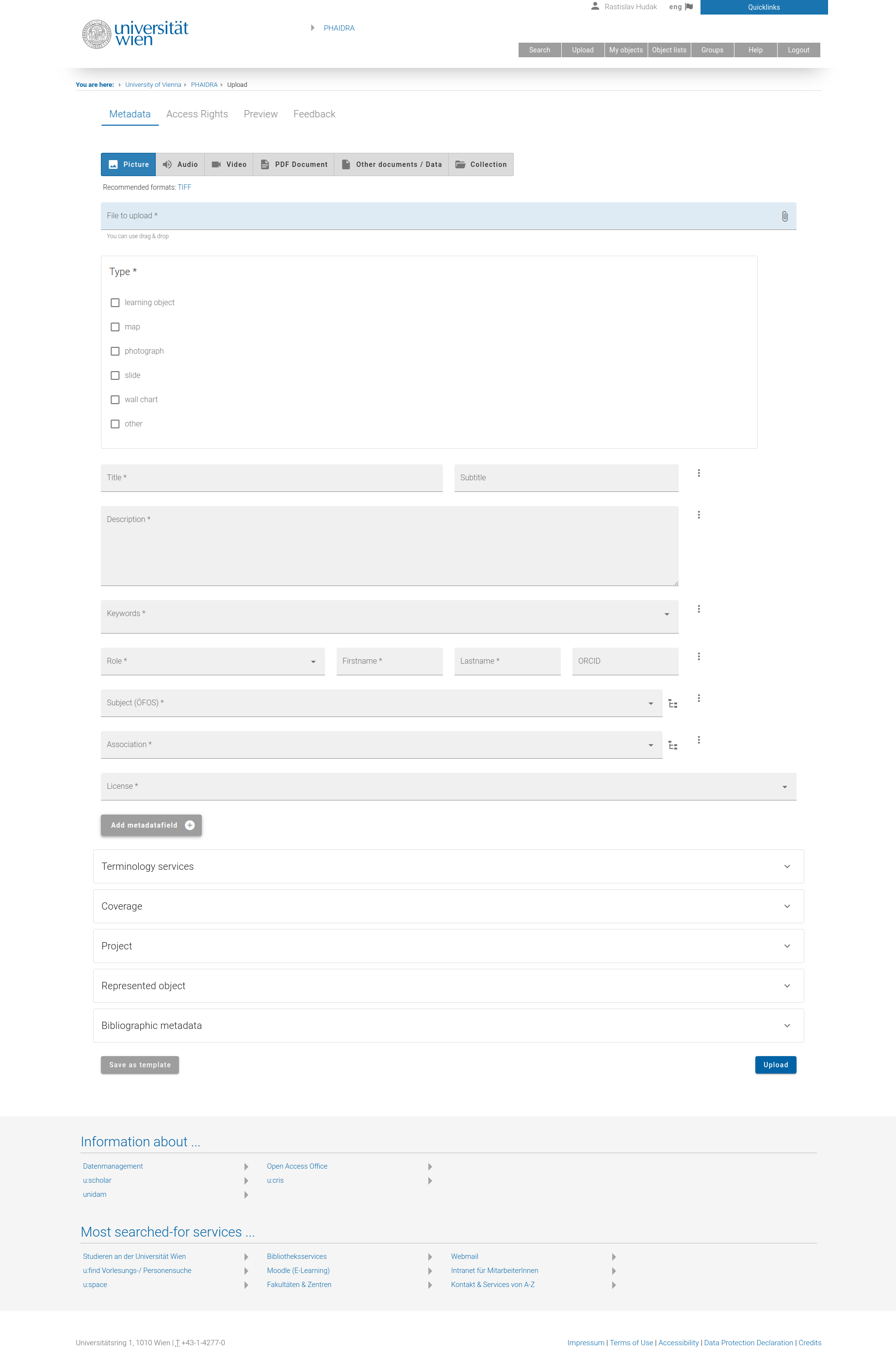
Here is how a typical submit form looks like
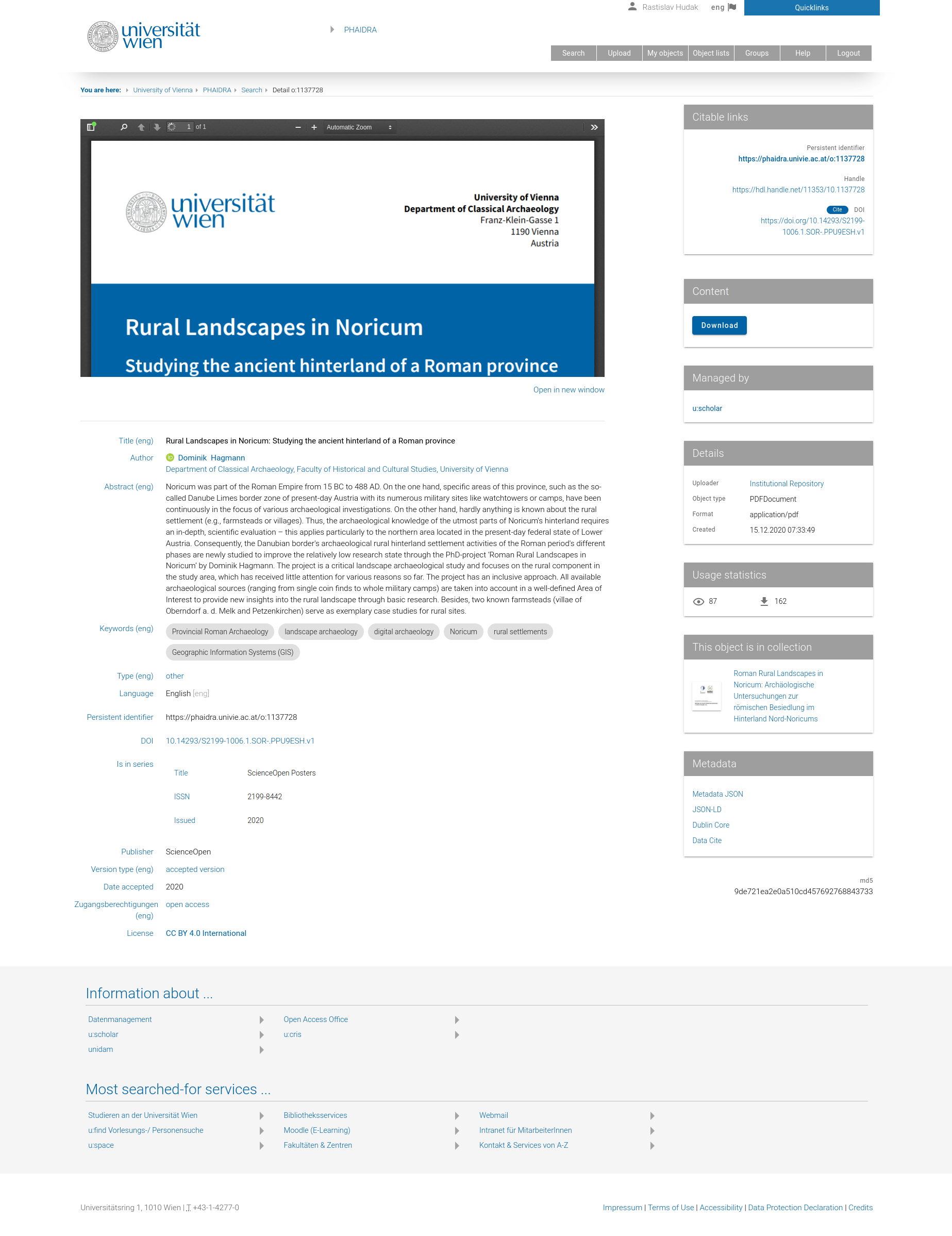
And this is the typical detail view
Monitoring
PHAIDRA makes use of the state of the art monitoring software like Grafana, Loki and Promtail, which are part of the code repository. We'd also typically use Prometheus for alerting (not part of the code repository).
Cronjobs
Cronjobs are set up for periodic maintenance tasks like removing expired access rights definitions, creating sitemaps, updating OAI-PMH records, backing-up databases, etc.
Other services
A productive repository instance needs services which are not, or cannot be part of PHAIDRA code. Alerting and backup are two examples which should definitely be set up.
Docked applications
Throughout the 15 years of PHAIDRA's history, multiple systems have been integrated with it. There are at least 3 different systems for thesis submit, ingest workflows have been developed from systems like Goobi or Moodle and metadata have been mapped from various repositories and catalogues. Some of the integrations make use of PHAIDRA API and some even PHAIDRA Vue Components. We call the latter "Docker applications". See Docked Applications for some examples.
Other components
As a central datahub, a repository often needs to be integrated with many other services in an institution. In case of PHAIDRA this can be implemented actively via PHAIDRA API, or the API can write a job in a custom queue for the external service to pick up and process. An example of services which are integrated in some PHAIDRA instances are a Handle server or an Opencast streaming server.
Harvesters
One of the primary missions of an open repository is dissemination. PHAIDRA uses the OAI-PMH interface through which metadata can be harvested in oai_dc and oai_openaire metadata schemas.